Por quê no brasil impera o imediatismo nas comissões técnicas de futebol?
No futebol, especificamente no Brasil impera o imediatismo dos times em relação ao trabalho das comissões técnicas. Logo, ao decorrer de um único ano de competição muitos times acabando interrompendo o ciclo de trabalho, trocando de técnico mais de uma vez.
confiabilidade
futebol
técnicos
autor
Pedro
Data de Publicação
15/04/2024
Apresentação
Introdução
No futebol, especificamente no Brasil impera o imediatismo dos times em relação ao trabalho das comissões técnicas. Logo, ao decorrer de um único ano de competição muitos times acabando interrompendo o ciclo de trabalho, trocando de técnico mais de uma vez. E alguns dos fatores são :
Recentes resultados ruins
Insatisfação da torcida
Estagnação do time
Ausência de conquistas
Mudanças na diretoria e presidência
Sendo assim, o objetivo desse trabalho é usar conceitos de confiabilidade para identificar quais variáveis tem impacto e qual a magnitude desse impacto. Utilizando algumas variáveis de estresse relacionadas ao desempenho e perfil dos times e treinador. Os dados foram capturados do site Transfermarket, contendo o histórico desde 2000 de treinadores dos 20 times atuais da série A do campeonato brasileiro, e também do Santos que está na série B.
Objetivos
Comparar adequação dos modelos Weibull e exponencial
Encontrar variável(is) que impacta significativamente e qual a sua magnitude
Interpretar Medidas de confiabilidade para o modelo proposto
Neste trabalho serão utilizadas as seguintes variáveis : Técnico (nome do treinador), Time (equipe do período de trabalho do treinador), Ano_Inicio (ano em que o treinador ingressou na equipe), Idade (idade do treinador no momento da contratação), Jogos_Ger (média de jogos disputados em equipes passadas), PPJ_Ger (média de pontos ganhos por jogo em trabalhos anteriores), PPJ (média de pontos quando saiu da equipe atual), tempos (número de jogos até a saída do treinador) e cens (são identificadas como censura se o treinador ainda está na equipe atualmente).
Mostre o Código
dados[sample(1:nrow(dados),size =15),]
Tecnico Time Idade Ano_Inicio PPJ_GER JOGOS_GER tempos cens
348 Paulo César Gusmão CRU 43 2005 NA NA 52 1
355 Renato Gaúcho VAS 42 2005 NA NA 71 1
155 Roger Machado GRE 40 2015 NA NA 74 1
97 Paulo César Carpegiani VIT 60 2009 1.230000 22.00000 18 1
152 Levir Culpi CAM 65 2018 1.592500 43.75000 17 1
598 Glauber Ramos GOI NA 2021 1.180000 34.00000 15 1
53 Ricardo Gomes SPFC 44 2009 1.670000 9.00000 56 1
117 Luiz Felipe Scolari CRU 51 2000 NA NA 9 1
238 Eduardo Barroca VIT 38 2020 1.450000 19.00000 9 1
560 Pintado CUI 56 2022 1.605000 29.50000 21 1
191 Celso Roth GRE 50 2008 1.326000 21.40000 43 1
108 Oswaldo de Oliveira BOT 61 2012 1.690000 17.00000 89 1
283 Mano Menezes SCCP 45 2008 1.600000 90.00000 59 1
512 Givanildo Oliveira AMM 70 2018 1.413333 40.66667 9 1
269 Caio Júnior BOT 46 2011 1.605000 38.00000 39 1
Seleção de Variáveis
Em alguns testes realizados utilizando seleção de variáveis verificando a significância da contribuição de cada uma delas para os modelos Weibull e Exponencial, verifica-se que as métricas que mais contribuiram para o modelo foram PPJ_Ger e PPJ. Sendo assim, foi criada uma nova variável que é a combinação linear entre elas, onde o PPJ e PPJ_Ger tem 80% e 20%, respectivamente da contribuição final dessa variável, que será a única a ser incluída no modelo, junto com os tempos e as censuras.
A partir dos p valores do TRV, rejeitamos H0 nas distribuições a um nível de significância de 5%, tendo indício de que os modelos complexos são mais adequados que os simples. Para decidir qual modelo escolher, observa-se a magnitude do TRV, onde o weibull foi o mais satisfatório, alcançando cerca de 7.51 unidades na estatística.
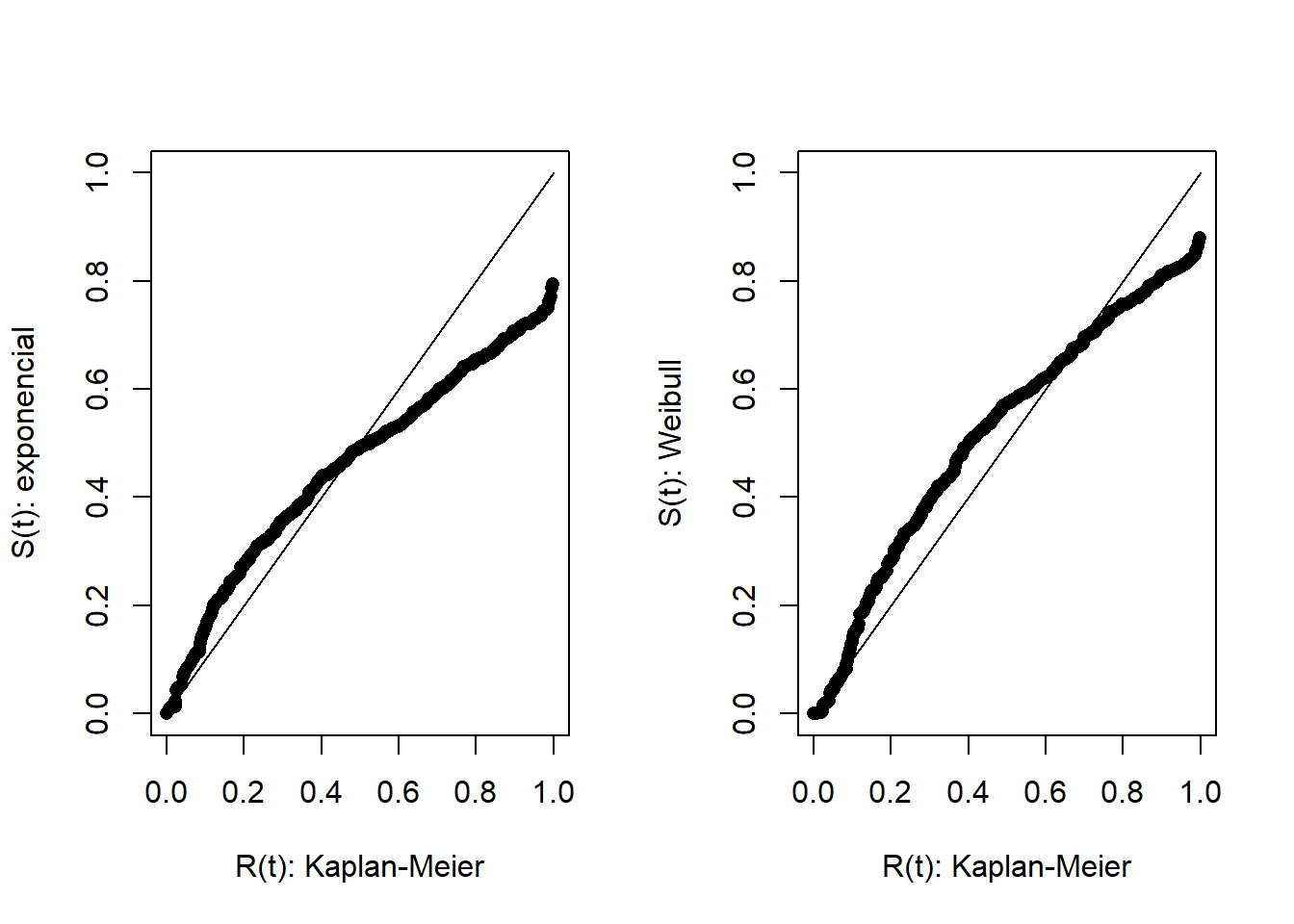
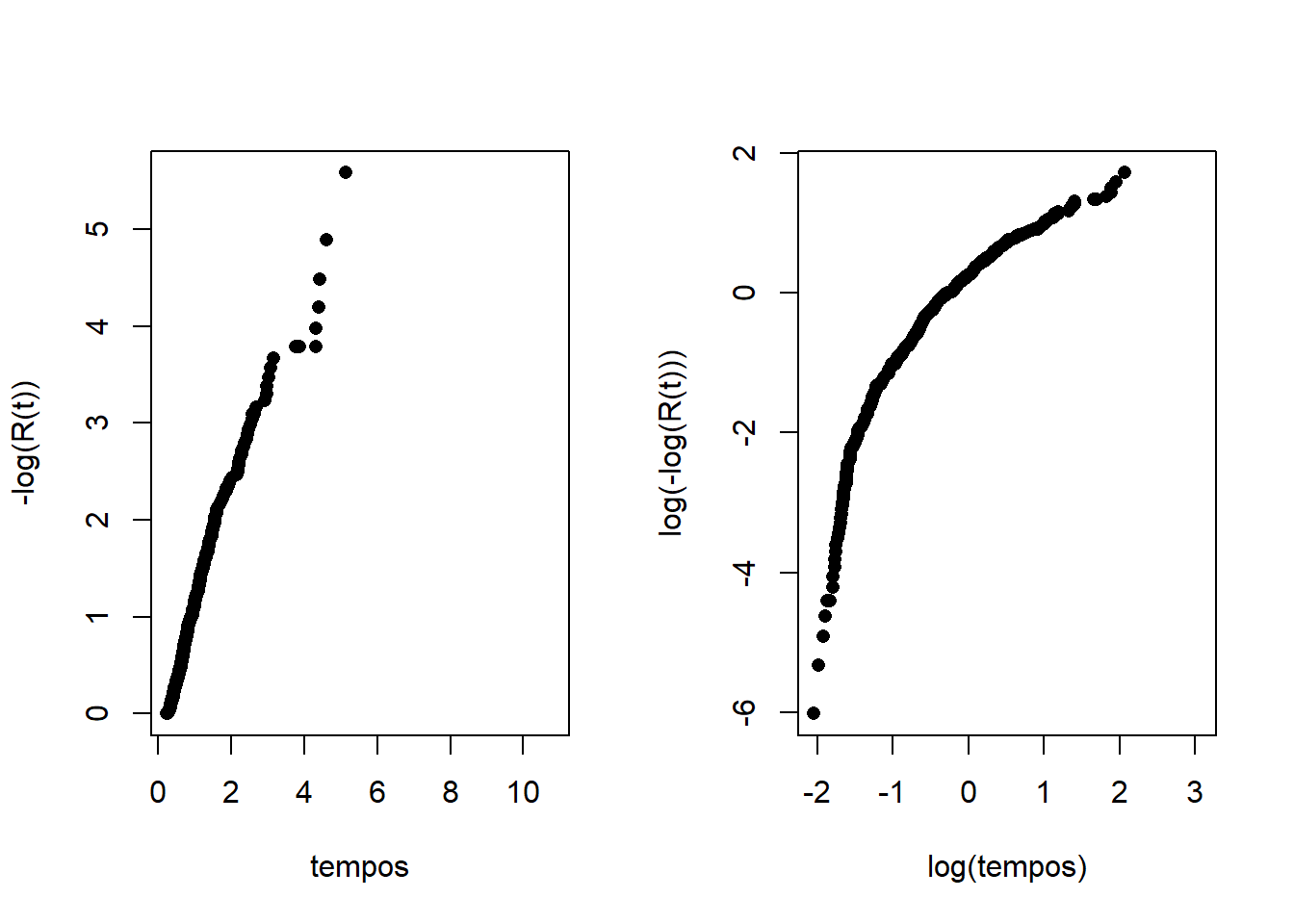
Avaliação Gráfica
Mostre o Código
attach(dados)x = dados$PPJ_CLres1 =exp( log(tempos)-coef(ajust1)[1]-coef(ajust1)[2]*x )res2 =exp( (log(tempos)-coef(ajust2)[1]-coef(ajust2)[2]*x )/ ajust2$scale )ekm1<-survfit(Surv(res1,cens)~1)ekm2<-survfit(Surv(res2,cens)~1)time1<-ekm1$timetime2<-ekm2$time R.kp1<-ekm1$survR.kp2<-ekm2$survR.exp<-exp(-time1/1) # Se o modelo exp for adequado entaos os residuos devem ter dist. exponencial(1)R.Weib <-exp(-(time2/1)) # Se o modelo weibull for adequado entaos os residuos devem ter dist. weibull(1,1)par(mfrow=c(1,2))plot(R.kp1, R.exp, pch=16, ylim=range(c(0.0,1)), xlim=range(c(0,1)), xlab ="R(t): Kaplan-Meier",ylab="S(t): exponencial")lines(c(0,1), c(0,1), type="l", lty=1)plot(R.kp2, R.Weib, pch=16, ylim=range(c(0.0,1)), xlim=range(c(0,1)), xlab ="R(t): Kaplan-Meier",ylab="S(t): Weibull")lines(c(0,1), c(0,1), type="l", lty=1)
Analisando os gráficos de R(t) vs S(t) e o de Linearização, percebe-se que o modelo Weibull é mais adequado.
Simulações e Medidas
Serão realizadas simulações considerando situações de técnicos que tiveram desempenho ruim, mediano e bom, tanto no time atual (ppj_atual) quanto no time anterior (ppj_anterior), onde vamos combinar essas situações, de modo que o técnico pode ter uma passagem ruim no time anterior e agora ele está bem, uma passagem anterior e atual medianas e entre outras situações. Para o desempenho ruim, mediano e bom os pontos por jogo (ppj) serão dados por 1.1, 1.4 e 1.8, respectivamente. Logo, a partir de todas as combinações possíveis formadas poderemos estimar medidas como MTTF, tempo mediano, confiabilidade até o tempo t e intervalo de confiança.
Mostre o Código
ppj_atual =c(rep(1.8,3),rep(1.4,3),rep(1.1,3))ppj_anterior =c(1.8,1.4,1.1,1.8,1.4,1.1,1.8,1.4,1.1)ppj_cl = (ppj_atual*0.8)+(ppj_anterior*0.2)MTTF =c(); tp =c(); t =c(); Rt =c(); LS =c(); LI =c()for(i in1:length(ppj_cl)){ grau = ppj_cl[i] p =0.5 MTTF[i] =exp(coef(ajust2)[1]+coef(ajust2)[2]*grau)*gamma(1+ajust2$scale) tp[i] =exp(coef(ajust2)[1]+coef(ajust2)[2]*grau)*(-log(1-p))^(ajust2$scale) t[i] =19 Rt[i] =round(exp(-(t/(exp(coef(ajust2)[1]+coef(ajust2)[2]*grau)))^(ajust2$scale)),4)*100 LS[i] =exp(log(exp(coef(ajust2)[1]+coef(ajust2)[2]*grau))+1.96*sqrt(vcov(ajust2)[1,1]+((grau^2)*vcov(ajust2)[2,2])+(2*grau*vcov(ajust2)[1,2]))) LI[i] =exp(log(exp(coef(ajust2)[1]+coef(ajust2)[2]*grau))-1.96*sqrt(vcov(ajust2)[1,1]+((grau^2)*vcov(ajust2)[2,2])+(2*grau*vcov(ajust2)[1,2])))}
Pela tabela, pode-se observar algumas situações bem interessantes. A primeira é que quando o treinador vem de uma passagem boa por um clube e, ele mantém as expectativas no time atual, o tempo mediano dele nesse clube é de aproximadamente 31 jogos, o tempo médio sem falhas é de cerca de 37 jogos, e o número de treinadores restantes após 19 jogo sé de aproximadamente 56.4%, e por fim é quase certo que o número de jogos desse tipo de treinador oscila em um intervalo de aproximadamente 36 a 46 jogos.
Quando comparado com um outro extremo onde temos um treinador que vem de um trabalho anterior bom e atualmente mal, o MTTF é de 28.4, tempo mediano de 23.5, diminuindo cerca de 7 jogos em relação ao exemplo de técnico anterior, além disso o intervalo passa a ser de 27 a 35 jogos.
Um técnico que tem tempo considerado mediano tanto no trabalho atual quanto no anterior, é quase certo que permaneça entre 30.5 e 36.3 não sendo tão diferente das demais combinações, com uma leve exceção para a primeira onde o técnico foi bem nos dois cenários.
Quando comparado os intervalos de confiança dos diferentes cenários, pode-se notar que o cenário onde o técnico foi bem em ambos os contextos têm intervalo que se difere apenas dos 3 últimos apresentados na tabela, onde o técnico obteve desempenho atual ruim em todos os cenários, e variando no anterior.
Evidenciando que em comparação com as demais combinações restantes, não há diferença ‘significativa’, mostrando que o número de jogos do comando técnico entre esses cenários não são diferentes. Logo a longevidade pode ser considerada semelhante se o técnico tem um desempenho atual mediano e bom, e um anterior bom, mediano ou ruim.
Conclusão
Em resumo o modelo escolhido foi bem satisfatório nas análises gráficas, no Likelihood Ratio Test e na seleção da variável preditora, permitindo o uso desse modelo para estimar diferentes contextos de técnicos, buscando obter estimativas de confiabilidade, entendendo o impacto que a performance tem na longevidade.
Melhorias
Buscar e criar mais variáveis
Testar essas novas variáveis no modelo
Coletar mais dados de times da segunda divisão
Pegar dados de competições europeias para comparação